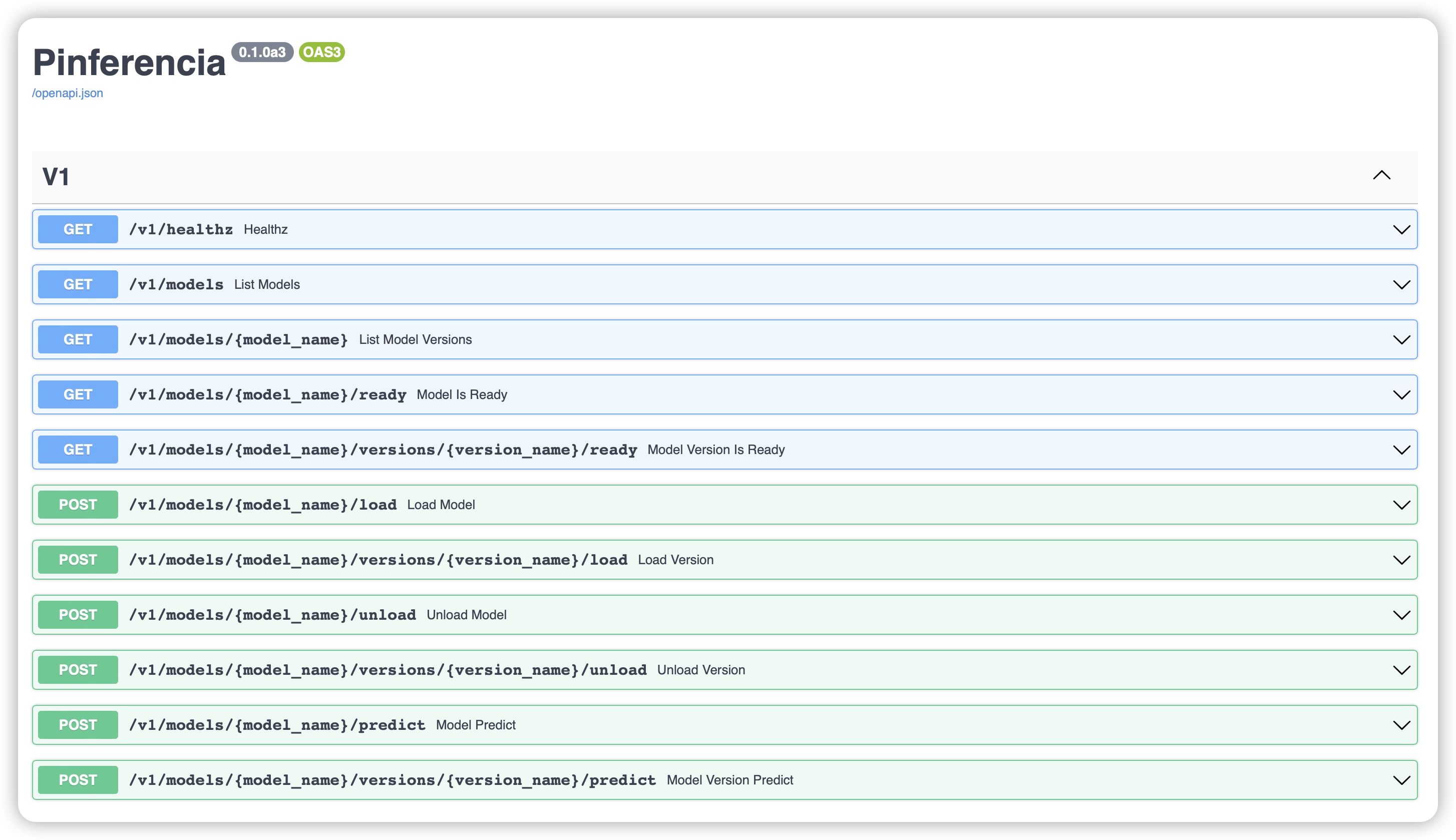
Welcome to Pinferencia¶
![]()
What is Pinferencia?¶

![]()

![]()
![]()
Straight forward. Simple. Powerful.
Three extra lines and your model goes online.
Pinferencia (python + inference) aims to provide the simplest way to serve any of your machine learning models with a fully functioning Rest API.
Features¶
Pinferencia features include:
- Fast to code, fast to go alive. Minimal codes to write, minimum codes modifications needed. Just based on what you have.
- 100% Test Coverage: Both statement and branch coverages, no kidding.
- Easy to use, easy to understand.
- Automatic API documentation page. All API explained in details with online try-out feature. Thanks to FastAPI and Starlette.
- Serve any model, even a single function can be served.
Try it now!¶
Install¶
$ pip install "pinferencia[streamlit]"
---> 100%
Create the App¶
app.py
from pinferencia import Server
class MyModel:
def predict(self, data):
return sum(data)
model = MyModel()
service = Server()
service.register(
model_name="mymodel",
model=model,
entrypoint="predict",
)
app.py
from pinferencia import Server
def model(data):
return sum(data)
service = Server()
service.register(
model_name="mymodel",
model=model,
)
app.py
import joblib
import uvicorn
from pinferencia import Server
# train your model
model = "..."
# or load your model
model = joblib.load("/path/to/model.joblib") # (1)
service = Server()
service.register(
model_name="mymodel",
model=model,
entrypoint="predict", # (2)
)
-
For more details, please visit https://scikit-learn.org/stable/modules/model_persistence.html
-
entrypointis the function name of themodelto perform predictions.Here the data will be sent to the
predictfunction:model.predict(data).
app.py
import torch
from pinferencia import Server
# train your models
model = "..."
# or load your models (1)
# from state_dict
model = TheModelClass(*args, **kwargs)
model.load_state_dict(torch.load(PATH))
# entire model
model = torch.load(PATH)
# torchscript
model = torch.jit.load('model_scripted.pt')
model.eval()
service = Server()
service.register(
model_name="mymodel",
model=model,
)
- For more details, please visit https://pytorch.org/tutorials/beginner/saving_loading_models.html
app.py
import tensorflow as tf
from pinferencia import Server
# train your models
model = "..."
# or load your models (1)
# saved_model
model = tf.keras.models.load_model('saved_model/model')
# HDF5
model = tf.keras.models.load_model('model.h5')
# from weights
model = create_model()
model.load_weights('./checkpoints/my_checkpoint')
loss, acc = model.evaluate(test_images, test_labels, verbose=2)
service = Server()
service.register(
model_name="mymodel",
model=model,
entrypoint="predict",
)
- For more details, please visit https://www.tensorflow.org/tutorials/keras/save_and_load
| app.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Run!¶
$ uvicorn app:service --reload
INFO: Started server process [xxxxx]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
Hooray, your service is alive. Go to http://127.0.0.1:8000/ and have fun.
Remember to come back to our Get Started class!