GPT2 - Text Generation Transformer: How to Use & How to Serve¶
What is text generation? Input some texts, and the model will predict what the following texts will be.
Sounds interesting. How can it be interesting without trying out the model by ourself?
How to Use¶
The model will be downloaded automatically
from transformers import pipeline, set_seed
generator = pipeline("text-generation", model="gpt2")
set_seed(42)
def predict(text: str) -> list:
return generator(text, max_length=50, num_return_sequences=3)
That's it!
Let's try it out a little bit:
predict("You look amazing today,")
And the result:
[{'generated_text': 'You look amazing today, guys. If you\'re still in school and you still have a job where you work in the field… you\'re going to look ridiculous by now, you\'re going to look really ridiculous."\n\nHe turned to his friends'},
{'generated_text': 'You look amazing today, aren\'t you?"\n\nHe turned and looked at me. He had an expression that was full of worry as he looked at me. Even before he told me I\'d have sex, he gave up after I told him'},
{'generated_text': 'You look amazing today, and look amazing in the sunset."\n\nGarry, then 33, won the London Marathon at age 15, and the World Triathlon in 2007, the two youngest Olympians to ride 100-meters. He also'}]
Let's have a look at the first result.
You look amazing today, guys. If you're still in school and you still have a job where you work in the field… you're going to look ridiculous by now, you're going to look really ridiculous." He turned to his friends
🤣 That's the thing we're looking for! If you run the prediction again, it'll give different results every time.
How to Deploy¶
Install Pinferencia¶
$ pip install "pinferencia[streamlit]"
---> 100%
Create the Service¶
| app.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
Start the Server¶
$ uvicorn app:service --reload
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: Started reloader process [xxxxx] using statreload
INFO: Started server process [xxxxx]
INFO: Waiting for application startup.
INFO: Application startup complete.
$ pinfer app:service --reload
Pinferencia: Frontend component streamlit is starting...
Pinferencia: Backend component uvicorn is starting...
Test the Service¶
Open http://127.0.0.1:8501, and the template Text to Text will be selected automatically.
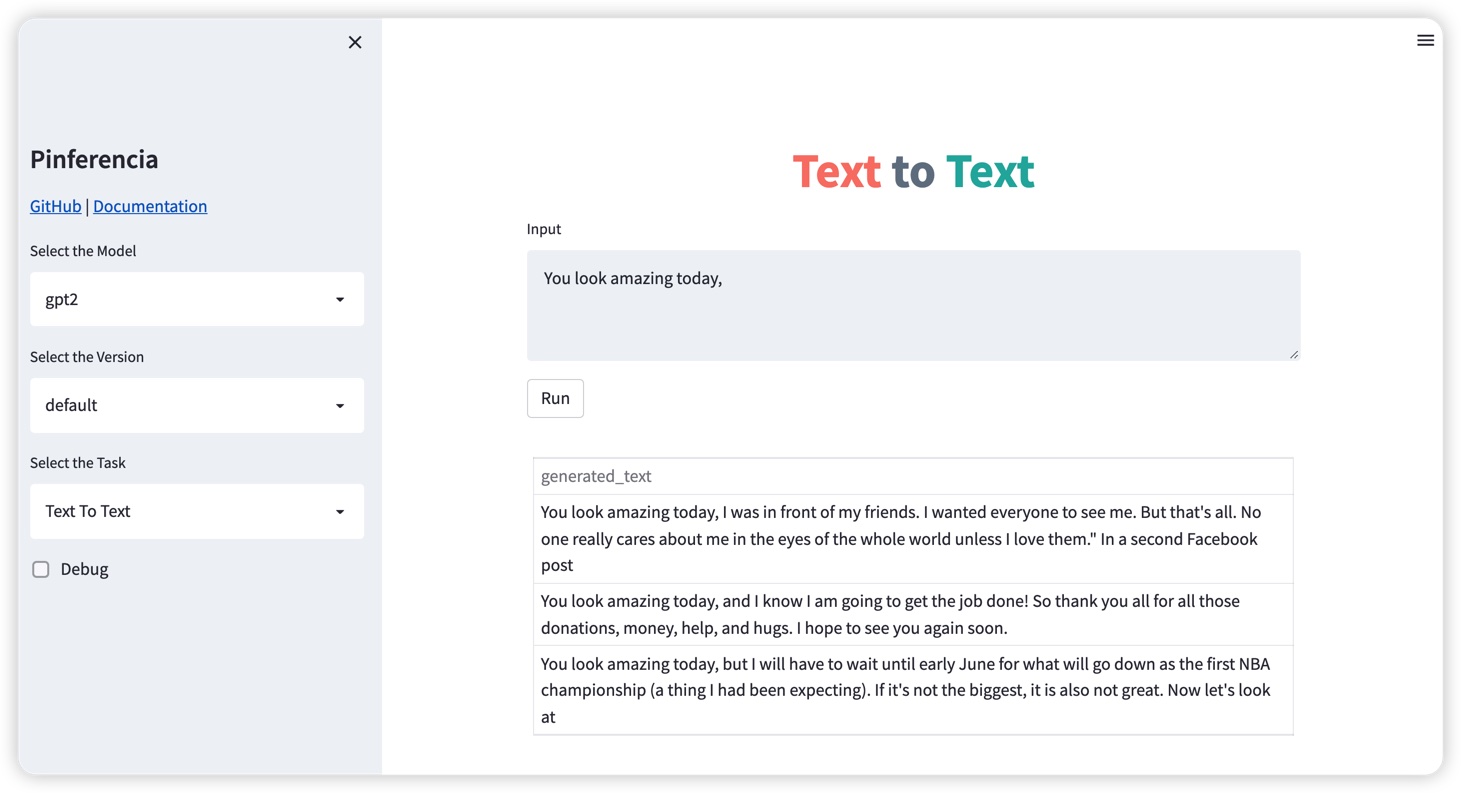
curl -X 'POST' \
'http://127.0.0.1:8000/v1/models/gpt2/predict' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"id": "string",
"parameters": {},
"data": "You look amazing today,"
}'
Result:
{
"id": "string",
"model_name": "gpt2",
"data": [
{
"generated_text": "You look amazing today, I was in front of my friends. I wanted everyone to see me. But that's all. No one really cares about me in the eyes of the whole world unless I love them.\"\n\nIn a second Facebook post"
},
{
"generated_text": "You look amazing today, and I know I am going to get the job done! So thank you all for all those donations, money, help, and hugs. I hope to see you again soon."
},
{
"generated_text": "You look amazing today, but I will have to wait until early June for what will go down as the first NBA championship (a thing I had been expecting). If it's not the biggest, it is also not great. Now let's look at"
}
]
}
| test.py | |
|---|---|
1 2 3 4 5 6 7 8 9 | |
Run python test.py and print the result:
Prediction: [
{
"generated_text": "You look amazing today, I was in front of my friends. I wanted everyone to see me. But that's all. No one really cares about me in the eyes of the whole world unless I love them.\"\n\nIn a second Facebook post"
},
{
"generated_text": "You look amazing today, and I know I am going to get the job done! So thank you all for all those donations, money, help, and hugs. I hope to see you again soon."
},
{
"generated_text": "You look amazing today, but I will have to wait until early June for what will go down as the first NBA championship (a thing I had been expecting). If it's not the biggest, it is also not great. Now let's look at"
}
]
Even cooler, go to http://127.0.0.1:8000, and you will have a full documentation of your APIs.
You can also send predict requests just there!