Bert
Many of you must have heard of Bert, or transformers. And you may also know huggingface.
In this tutorial, let's play with its pytorch transformer model and serve it through REST API
How does the model work?¶
With an input of an incomplete sentence, the model will give its prediction:
Paris is the [MASK] of France.
Paris is the capital of France.
Let's try it out now
Prerequisite¶
Please visit Dependencies
Serve the Model¶
Install Pinferencia¶
First, let's install Pinferencia.
pip install "pinferencia[streamlit]"
Create app.py¶
Let's save our predict function into a file app.py and add some lines to register it.
| app.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
Run the service, and wait for it to load the model and start the server:
$ uvicorn app:service --reload
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: Started reloader process [xxxxx] using statreload
INFO: Started server process [xxxxx]
INFO: Waiting for application startup.
INFO: Application startup complete.
$ pinfer app:service --reload
Pinferencia: Frontend component streamlit is starting...
Pinferencia: Backend component uvicorn is starting...
Test the service¶
Open http://127.0.0.1:8501, and the template Text to Text will be selected automatically.
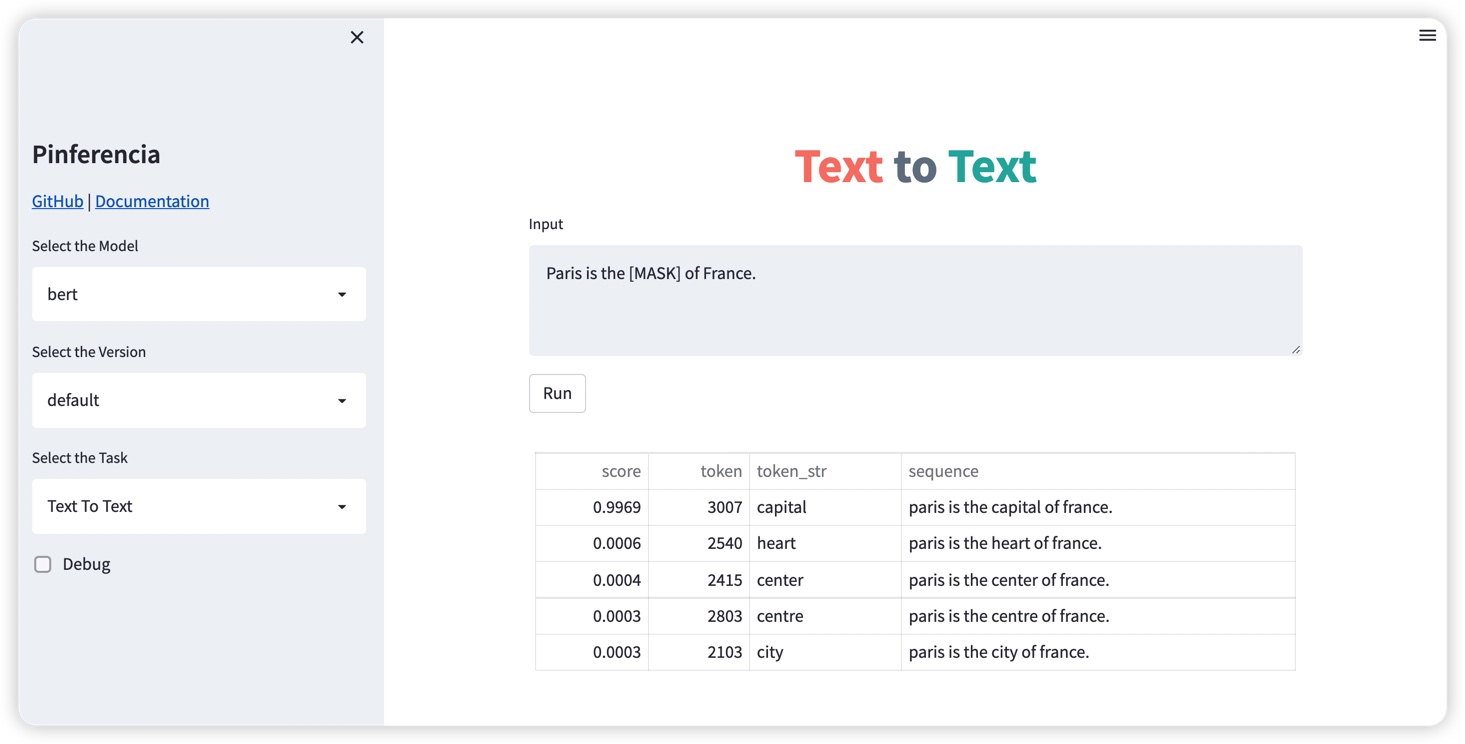
Request
curl --location --request POST \
'http://127.0.0.1:8000/v1/models/bert/predict' \
--header 'Content-Type: application/json' \
--data-raw '{
"data": "Paris is the [MASK] of France."
}'
Response
{
"model_name":"bert",
"data":"Paris is the capital of France."
}
Create the test.py.
| test.py | |
|---|---|
1 2 3 4 5 6 7 8 | |
$ python test.py
{'model_name': 'bert', 'data': 'Paris is the capital of France.'}
Even cooler, go to http://127.0.0.1:8000, and you will have a full documentation of your APIs.
You can also send predict requests just there!