启动一个 JSON 模型¶
现在先让我们尝试一个简单的例子,让你来熟悉 Pinferecia.
定义 JSON 模型¶
让我们先创建一个文件 app.py.
下面就是这个 JSON 模型.
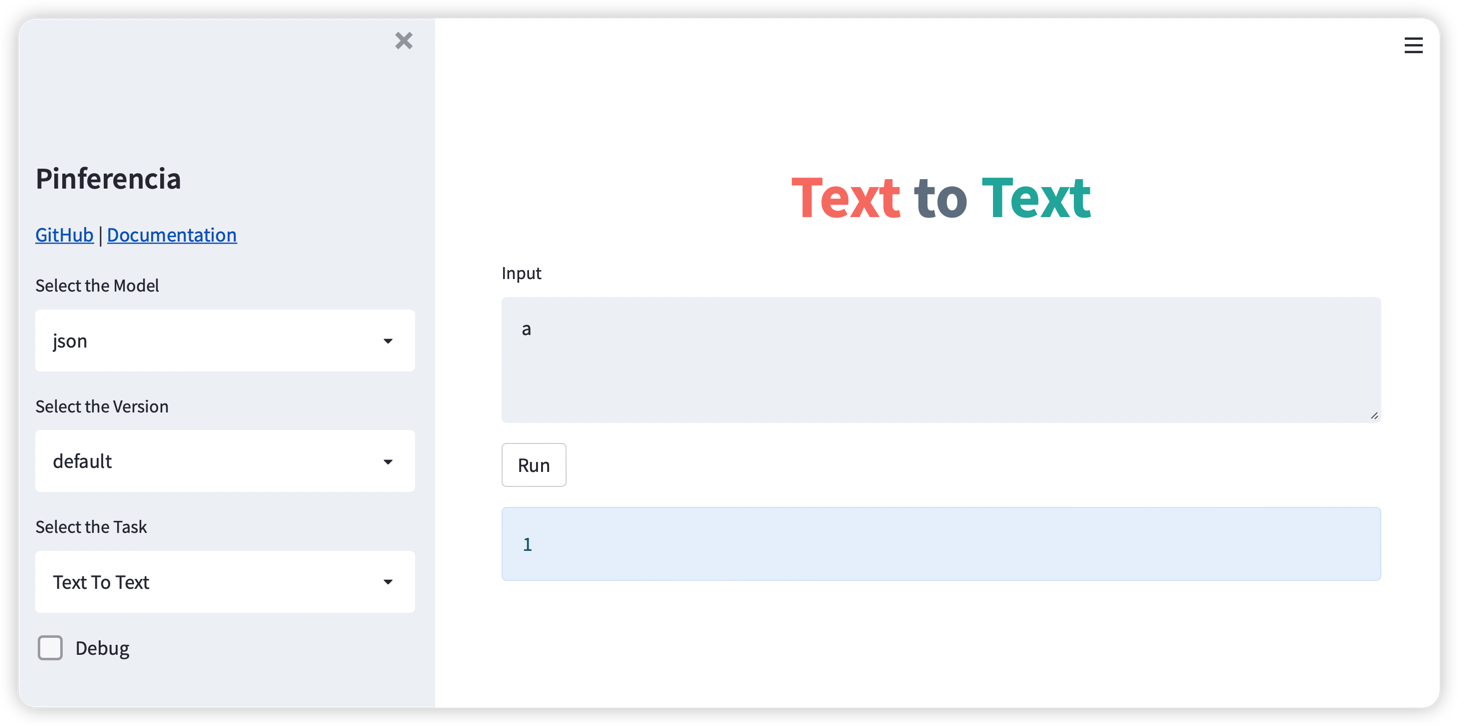
输入是a返回1, 输入b返回2, 其他输入返回0。
| app.py | |
|---|---|
1 2 3 4 | |
- 您可以使用 Python 3
Type Hints来定义模型服务的输入和输出。 在 Define Request and Response Schema 中查看Pinferencia如何利用Type Hints的。
创建服务并注册模型¶
首先从 pinferencia 导入 Server , 然后创建一个server实例并注册 JSON 模型.
| app.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
model_name, entrypoint 和 task 是什么意思?
model_name 你给这个模型取的名字。 这里我们取名 json, 对应的这个模型的地址就是 http://127.0.0.1:8000/v1/models/json.
如果关于API你有什么不清楚的,你可以随时访问下面将要提到的在线API文档页面。
entrypoint predict 意味着我们会使用 JSON 模型 的 predict函数来预测数据。
task 指示模型正在执行的任务类型。 如果提供了模型的task,将自动选择相应的前端模板。 模板的更多细节可以在前端要求中找到
启动服务¶
$ uvicorn app:service --reload
INFO: Started server process [xxxxx]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
打开浏览器访问:
-
http://127.0.0.1:8501, 你拥有了可以与你模型交互的图形介面。
-
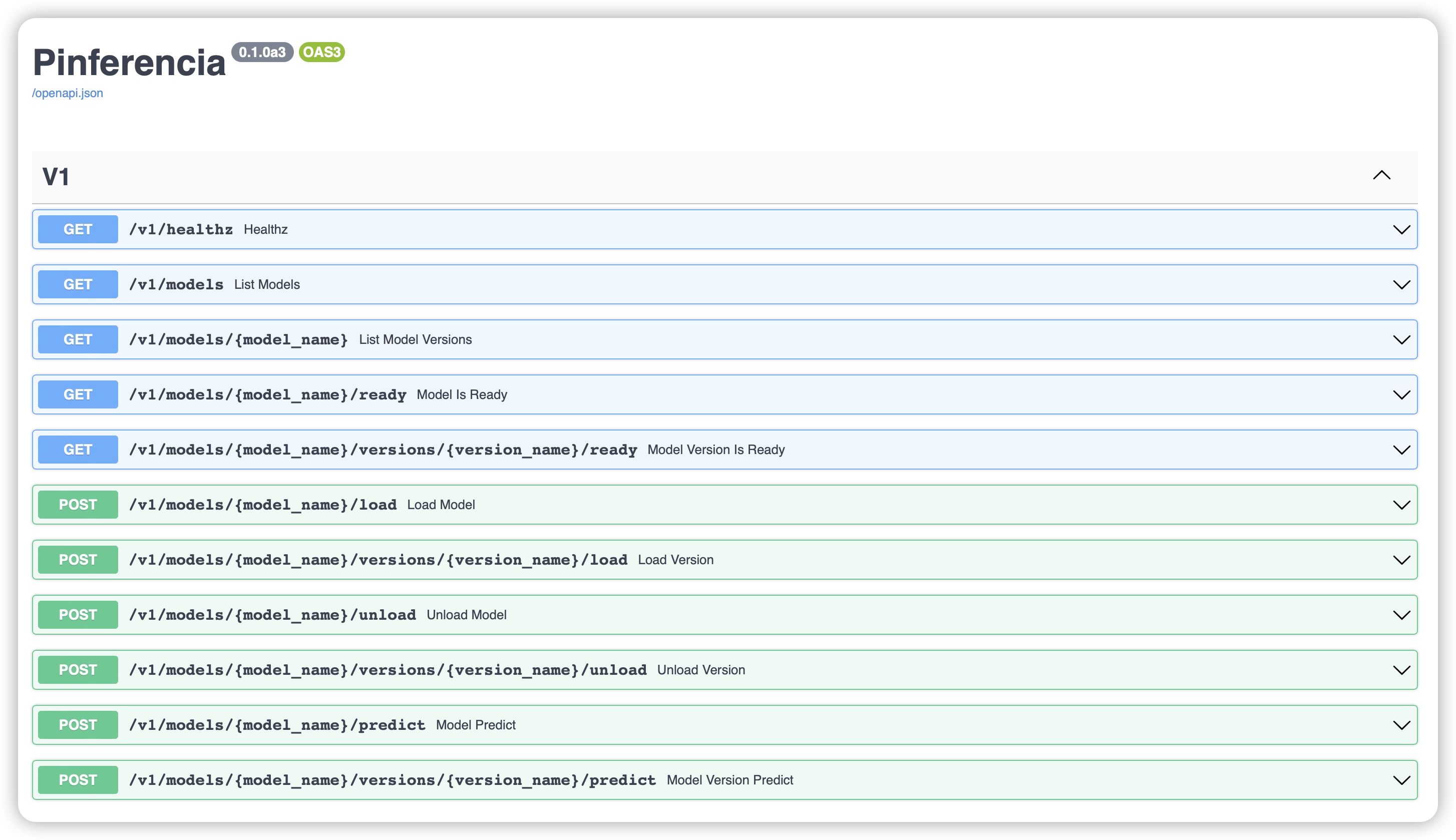
http://127.0.0.1:8000, 现在你拥有了一个自动生成的 API 文档页面!
FastAPI 和 Starlette
Pinferencia 基于 FastAPI,其又基于 Starlette.
多亏了他们,您将拥有一个带有 OpenAPI 规范的 API。这意味着您将拥有一个自动文档网页,并且客户端代码也可以自动生成。
默认文档地址在:
您可以查看 API 规范,甚至可以自己 试用 API!
使用前端介面¶
测试 API¶
使用下面的代码创建一个test.py。
提示
你需要安装 requests.
pip install requests
| test.py | |
|---|---|
1 2 3 4 5 6 7 8 | |
运行脚本并检查结果.
$ python test.py
{'model_name': 'json', 'data': [1]}
现在让我们再添加两个输入,并让打印更漂亮.
| test.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 | |
再次运行脚本并检查结果。
$ python test.py
| Input | Prediction |
|----------|---------------|
| a | 1 |
| b | 2 |
| c | 0 |